Experiment result · s43 selection-robustness (2026-06-09, for review)
Pre-registered diagnostic (ADR-0095). The decision rule (verdicts,
frac = 0.95,RATE_MIN = 0.10, tie-breaks) was frozen before the run (S05 plan,plan_reviewPASSED, Meeting 268) and exercised unchanged. Scope bounds: one fold (fold-3), gross cost (cost_atr = 0.0), GBDT (LightGBM + CatBoost; XGBoost not evaluable),defi_top5.⛔ STATUS: STOP pending S09 — DO NOT close S05, DO NOT record ABANDON.
s43ran withskip_phase_a=false→ it consumes the s18 replay, which A6 flaggeds18_status=FAILon 5/5 cells. All curves below are computed on that replay, whose fidelity S09 will test (prior: 5/5 FAIL → S09 may not clear it). The gate verdict as computed holds; its interpretation as a property of the signal is SUSPENDED until S09 lifts the asterisk. If S09 returnsCANONICAL_DIVERGENCE, these inputs are corrupted and the verdict is void.Revision — v0.1 initial; v0.2 correctness pass (STOP pending S09, recency/bootstrap caveats); v0.3 / v2 per-crypto mining (per-crypto robustness, EV-rate frontier, constrained
M, monotonicity, recency, units, 5 figures); v0.4 / v3 (this) — referee round 2: the per-crypto mining is held to the same standard as the config axis. The winner's curse it corrects on the config axis is re-imported on the crypto axis (10 cells) and the draw axis (recency = 1 of 6–12 draws): 1/10 inner-significant (ARB-LGB, CI low +0.008) is exactly chance at ~5 %; no multiplicity correction. So the per-crypto positives are hypothesis-generating, not a designated target (§5.4). CatBoost's gateMis explained as a degenerate single-trade corner (§5.2). Monotonicity needs a permuted-label null (§5.3).Muses a binary TP/SL label (time-barrier closes charged the full SL — §3). §9 re-discounted accordingly.
Abstract¶
Question. Does any apparent edge of the GBDT entry signal survive the production HPO's per-crypto selection instability on the pinned fold (winner's curse on the config axis)?
Methods. One diagnostic__s43 run (defi_top5/fold-3, gross cost_atr=0.0). Per family, the
production HPO draws are replayed and a selection bootstrap (B_sel=200, inner = (crypto, sub-block))
estimates p_pos = fraction of selection resamples with max net expectancy M > 0 at a non-degenerate
trade rate (rate ≥ 0.10). Robust-positive requires p_pos ≥ 0.95. v2 re-runs the same pure
functions per crypto on the run's persisted S3 predictions (no new run) for the per-crypto
decomposition + EV-vs-rate frontier. M is in ATR units / trade (TP=+1.5, SL=−0.5 ATR; break-even
precision = 25 %, gross).
Results. Portfolio: no family selection-robust positive (robust_pos = []) → verdict
C_FRAGILE_TO_SELECTION → STOP. LightGBM fragile (p_pos = 0.005), CatBoost unstable
(p_pos = 0). Per-crypto (the half the portfolio hid): on the most-recent config, the
high-confidence tail discriminates — at θ ≈ 0.25 / rate 10–16 %, precision reaches 0.29–0.33
(LightGBM, 4/5 cells gross-positive) and 0.33–0.41 (CatBoost, 5/5 cells gross-positive), all above the
25 % break-even, with EV rising monotonically as θ tightens (signal in the tail, not noise). But this
is not established as an edge: it is not selection-robust (p_pos ≈ 0 everywhere except ARB-LightGBM
at 0.16, still ≪ 0.95), inner-underpowered (selection CIs straddle zero — only ARB-LightGBM's recency
cut is inner-significant, M = +0.155, CI [+0.008, +0.309] at 14.6 % rate), and gross (cost erodes a
thin +0.1–0.3 ATR margin).
Conclusion. The pre-registered gate correctly does not PROMOTE — there is no selection-robust,
inner-significant, non-degenerate edge at gross cost on fold-3. The per-crypto recent-config positivity is
hypothesis-generating, not a result: held to the config-axis standard it is a post-hoc cherry-pick
across 10 cells × draws (1/10 inner-significant = chance; the recent draw is unrepresentative since
selection p_pos ≈ 0 — §5.4), and it is gross + binary-M. So the honest reading is absence of evidence,
not evidence of absence in both directions: not "tradable on UNI/ARB," not "signal dead." The candidate
worth a pre-registered high-power test is the generic high-confidence-tail mechanism (meta-labeling /
top-confidence band, EK) — not abandonment, not the post-hoc cells. All of this is gated behind
S09 (A6).
1. Introduction¶
A signal is tradable only if a deployable configuration nets a positive edge after cost. s43 r3(b) asks
the prior, cheaper question: is any edge robust to the production HPO's per-cycle re-draw of
hyperparameters (a stochastic process, not a fixed model — the S05 r3 finding)? An edge visible for one
lucky draw is a winner's-curse artefact on the config axis. The gate is necessary-not-sufficient: PASS
licenses multi-fold spend; STOP forgoes it. This report adds (v2) the per-crypto decomposition and the
EV-vs-rate frontier, mined from the same run — because a portfolio verdict can hide single-asset
structure (the cost-sensitivity report on this universe showed dispersion dominates).
2. Hypotheses & pre-registration¶
Frozen before the run (ADR-0095, plan_review PASSED, Meeting 268):
- H (selection robustness). An edge is a signal property iff
M > 0at a non-degenerate rate in≥ frac = 0.95of selection resamples. - Thresholds (frozen).
frac = 0.95,RATE_MIN = 0.10,B_sel = 200,MIN_DRAWS_PER_CRYPTO = 2. - Decide on significance, never the point estimate (s43 r2.7 fix) —
p_poskeys on the inner CI and the selection distribution, not onM_obs. This is load-bearing for §5 (a recent-drawM_obs > 0does not count unless it is selection-robust and inner-significant). - Two scope bounds.
evaluable_families = {LightGBM, CatBoost}(XGBoost excluded);model_class = GBDT.
3. Data & setup¶
| Item | Value |
|---|---|
| Run | diagnostic__s43 manual__2026-06-09T11:55:11+00:00 (done 14:53Z), image 1cba660 |
| Universe / fold | defi_top5 (UNI, OP, ARB, AAVE, LDO USDC) / fold-3, ATR0.5_1.5_H4 |
| Cost | gross cost_atr = 0.0 |
| Families | LightGBM, CatBoost — both assessable; XGBoost excluded |
| HPO draws/crypto | LGB {UNI 12, OP 8, ARB 7, AAVE 8, LDO 8}; CB {UNI 10, OP 8, ARB 6, AAVE 7, LDO 6} |
| Selection bootstrap | B_sel = 200, inner (crypto, sub-block) |
M units |
ATR / trade (TP=+1.5, SL=−0.5 ATR), gross → break-even precision = 25 % — binary-label model: M = p·1.5 − (1−p)·0.5 − cost, so triple-barrier time-barrier (H4) closes are charged the full −0.5 SL (their realized PnL ∈ [−0.5,+1.5] is not captured). M and the 25 % break-even are therefore an approximation (likely conservative for positive cells); the time-close fraction is not measured here (follow-up). Lead with M, not precision-vs-25 %. |
| Verdict provenance | gate XCom (S43PrefilterVerdict) + Loki s43_gate_outcome; per-crypto recompute from S3 predictions (Appendix A) |
Cohort complete (5/5), both families, draws ≥ minimum on every crypto.
4. Methods¶
Per family, production HPO draws are retrained on fold-3; the selection bootstrap resamples whole draws
(outer) and (crypto, sub-block) units (inner) to estimate the selection distribution of M = max_θ E(θ).
p_pos counts a resample positive iff the inner CI low > 0 and rate ≥ RATE_MIN. v2 calls the same pure
functions (selection_bootstrap, theta_curve, envelope_M) per single crypto on the run's S3
predictions (Appendix A) — zero new run. We also report, per crypto, the EV-vs-rate frontier (the θ
curve), the constrained max{M : rate ≥ 0.10}, and the recency cut (most-recent draw).
5. Results¶
5.1 Portfolio gate (pre-registered verdict)¶
event=s43_gate_outcome status=C_FRAGILE_TO_SELECTION gate=STOP cost_atr=0.0 frac=0.95 B_sel=200
robust_pos=() fragile=('lightgbm',)
per_family_class = {lightgbm: fragile, catboost: unstable}
robust_pos = []. LightGBM fragile (p_pos = 0.005, M_median = +0.22 but rate_at_median =
0.88 %); CatBoost unstable (p_pos = 0, M_median = +1.0 but rate_at_median = 0.08 %). The pooled
positivity is a degenerate-rate artefact (trades < 1 % of candles); once the 10 % floor applies it
collapses → C_FRAGILE_TO_SELECTION → STOP (no multi-fold cold-capture). STOP is a resource decision,
not a closure (banner).
5.2 Per-crypto decomposition — the half the portfolio hid¶
Robustness (what the gate decides on) — per-crypto selection bootstrap:
| Family / crypto | p_pos |
selection CI of M |
recency M (inner CI, rate) |
inner-significant? |
|---|---|---|---|---|
| LGB / UNI | 0.00 | [+0.045, +0.362] (all +) | +0.134 ([−0.256, +0.531], 11 %) | no (underpowered) |
| LGB / OP | 0.00 | [+0.129, +0.50] | +0.129 ([−0.057, +0.353], 14 %) | no |
| LGB / ARB | 0.16 | [−0.083, +0.155] | +0.155 ([+0.008, +0.309], 15 %) | YES |
| LGB / AAVE | 0.00 | [0.0, +0.198] | +0.075 ([−0.096, +0.268], 22 %) | no |
| LGB / LDO | 0.00 | [−0.074, +0.25] | −0.074 (neg) | no |
| CB / all 5 | 0.00 | positive but at degenerate rate_median 0.5–6 % |
recency rate 0.1–2 % | no |
Only ARB-LightGBM is selection-robust to any degree (p_pos = 0.16, still ≪ 0.95) and its recency
cut is inner-significant positive. UNI-LightGBM is a near-miss: its selection CI of M is
entirely positive at a deployable 21 % rate, but inner-underpowered (p_pos = 0). The portfolio
p_pos = 0.005 reflects the pooled selection envelope, not an average of per-crypto p_pos (the family
M pools all cryptos per selection resample, so it is not mean(per-crypto p_pos) — ARB's 0.16 does
not carry the pool); the pooled value sits near the floor because most cells contribute no robust positive.
Point estimate (recent config) — constrained max{M : rate ≥ 0.10} on the most-recent draw:
| Family | UNI | OP | ARB | AAVE | LDO |
|---|---|---|---|---|---|
| LGB (EV @ rate, prec) | +0.135 @ 11 %, 0.32 | +0.129 @ 14 %, 0.31 | +0.155 @ 15 %, 0.33 | +0.075 @ 22 %, 0.29 | −0.074 @ 28 %, 0.21 |
| CB (EV @ rate, prec) | +0.311 @ 16 %, 0.41 | +0.163 @ 16 %, 0.33 | +0.253 @ 11 %, 0.38 | +0.234 @ 13 %, 0.37 | +0.255 @ 12 %, 0.38 |
On the recent config, 4/5 LightGBM and 5/5 CatBoost cells are gross-positive at a deployable rate, with precision above the 25 % break-even (0.29–0.41). This is a point estimate on one post-hoc-selected draw across 10 cells, not an established edge (§5.3–§5.4).
CatBoost's gate M is a degenerate single-trade corner (not a contradiction). The robustness table
(§5.2 top, rate 0.1–2 %) and the point table (rate 11–16 %) are two different θ on the same curve: the
gate's M = max_θ E(θ) is unconstrained, so for CatBoost it lands on the extreme corner (e.g.
UNI-CB θ=0.9: 1 trade, won, EV = +1.5, precision = 1.0) — which is why CB's m_median = +1.0,
sel_ci = [0.5, 1.5] are degenerate-corner artefacts the gate correctly classes unstable. The
constrained max{M : rate ≥ 0.10} picks a lower-θ point (UNI-CB θ=0.6, rate 16 %, prec 0.41). Verified
data-side: CatBoost's precision-vs-rate is smooth and rising (not flat), so the deployable-rate positive
is a real curve feature on the recent draw — but see §5.4 for why that does not make it an edge.
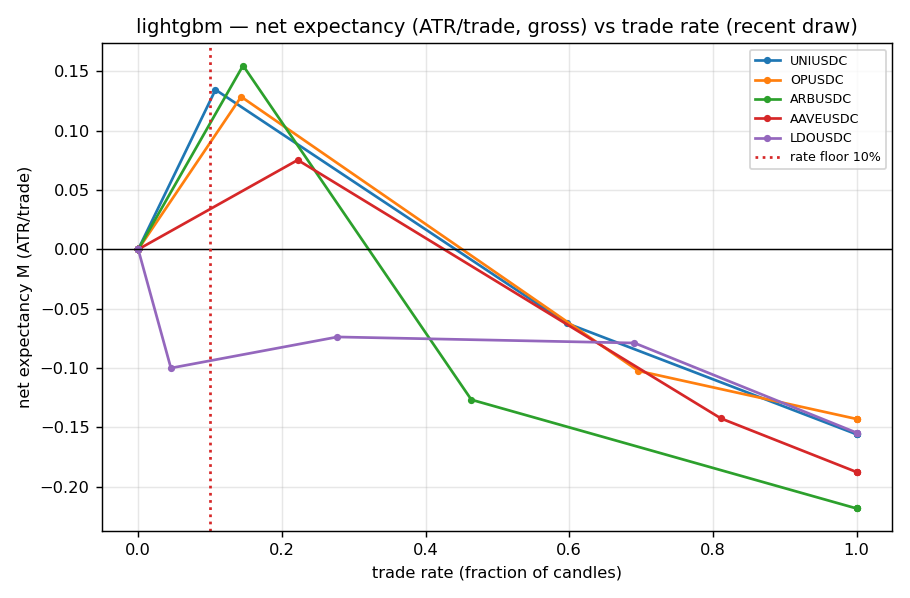 Figure 1. LightGBM net expectancy (ATR/trade, gross) vs trade rate, per crypto (recent draw). Positive
EV lives in a thin band at high θ / ~10–15 % rate; at low θ the model trades everything at a loss, and
above θ≈0.25 the rate is 0 (the model's
Figure 1. LightGBM net expectancy (ATR/trade, gross) vs trade rate, per crypto (recent draw). Positive
EV lives in a thin band at high θ / ~10–15 % rate; at low θ the model trades everything at a loss, and
above θ≈0.25 the rate is 0 (the model's p_buy never exceeds ~0.30 — no headroom).
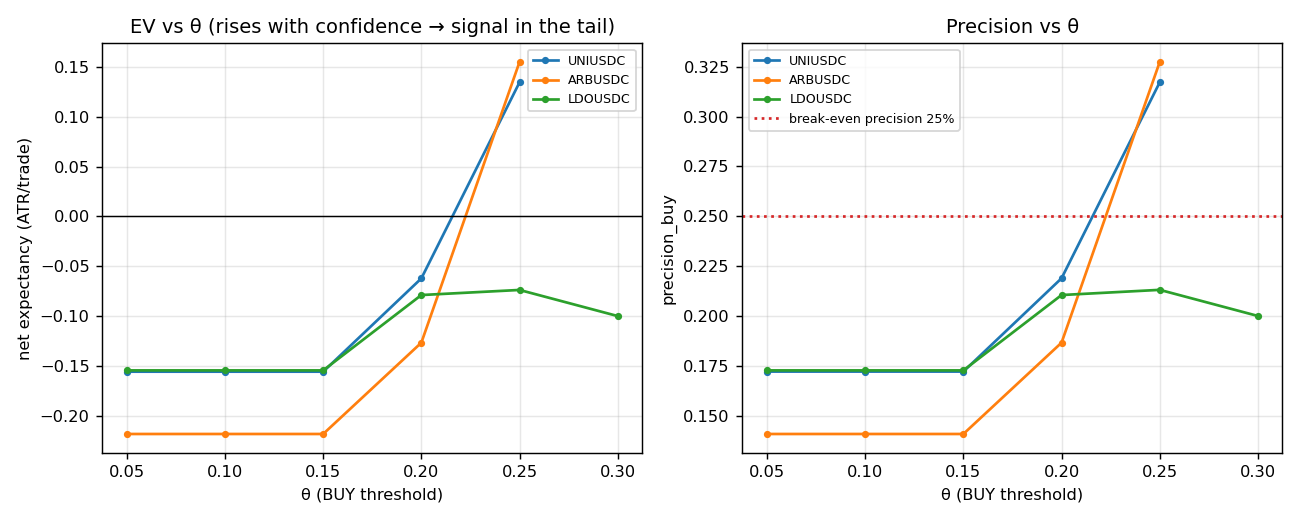 Figure 5. EV and precision rise (≈monotonically) as θ tightens (UNI/ARB/LDO-LGB). This is suggestive
of tail discrimination, not establishing it: a rising precision(θ) is expected under even weak
calibration and can emerge from tail noise + θ selection. A proper claim needs a permuted-label null
(a shuffled-
Figure 5. EV and precision rise (≈monotonically) as θ tightens (UNI/ARB/LDO-LGB). This is suggestive
of tail discrimination, not establishing it: a rising precision(θ) is expected under even weak
calibration and can emerge from tail noise + θ selection. A proper claim needs a permuted-label null
(a shuffled-y model should show no monotone tail) or a confidence band on precision(θ) — neither is
run here (follow-up).
5.3 Why the point-positivity is NOT an edge (reconciliation)¶
The recent-draw point estimates (§5.2 lower table) look strong, yet the gate is STOP — these are not in contradiction; they are the two halves of the same finding:
- Not selection-robust. Across the HPO draws, positivity vanishes (
p_pos ≈ 0): the recent config is not representative — other draws are degenerate or negative. This is exactly the winner's curse the gate is built to catch (per-registered: decide on the selection distribution, not one draw). - Inner-underpowered. Where the central
Mis positive at a deployable rate (UNI, OP, AAVE-LGB), the inner CI straddles zero — not established. Only ARB-LGB's recency clears inner significance. - Gross.
cost_atr = 0; a real round-trip would erode a +0.1–0.3 ATR margin (and raise the break-even precision above 25 %), likely flipping the thin band negative.
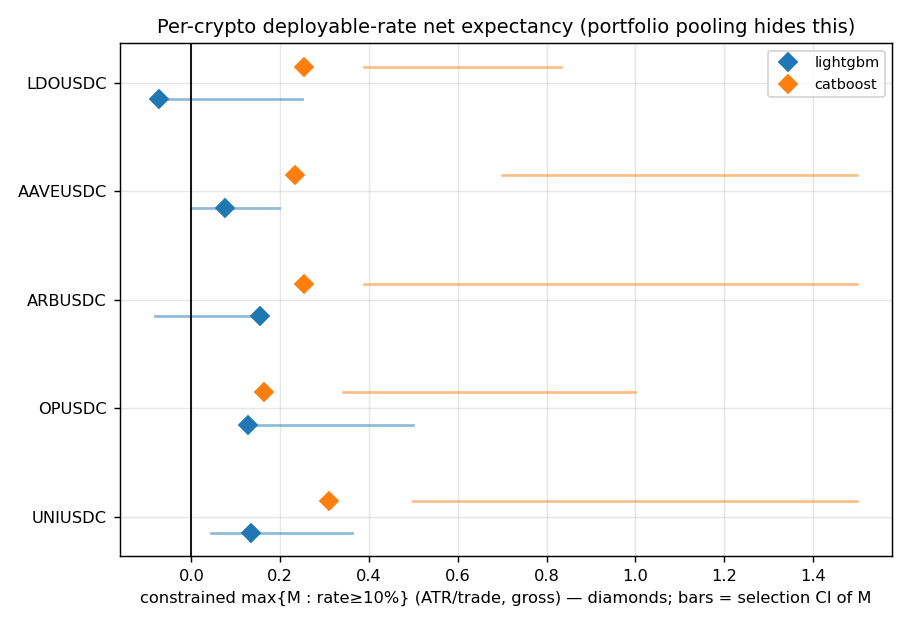 Figure 2. Constrained
Figure 2. Constrained max{M : rate ≥ 10 %} per crypto with selection CI. Dispersion dominates; the
diamonds are point estimates, the bars (selection CI) show most straddle zero.
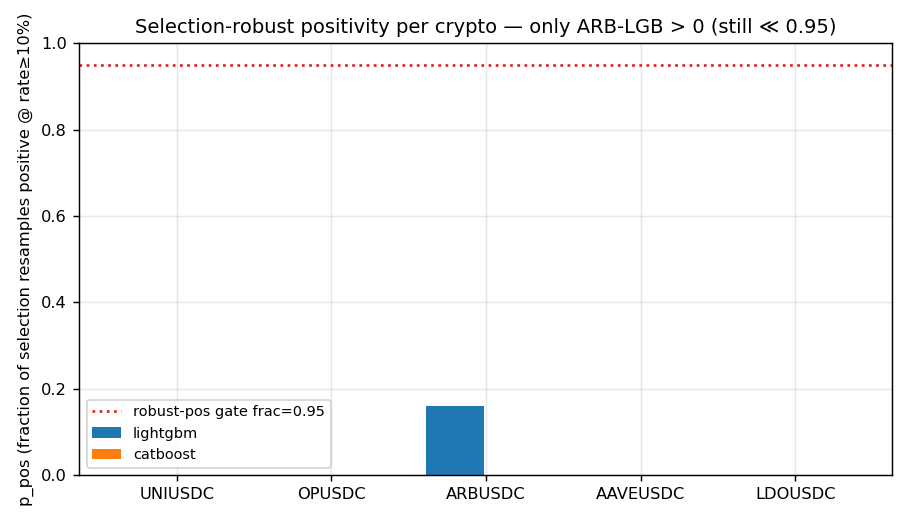 Figure 3.
Figure 3. p_pos per crypto vs the 0.95 robust-positive gate. Only ARB-LGB > 0 (0.16) — and still far
below the gate. Every other cell is 0.
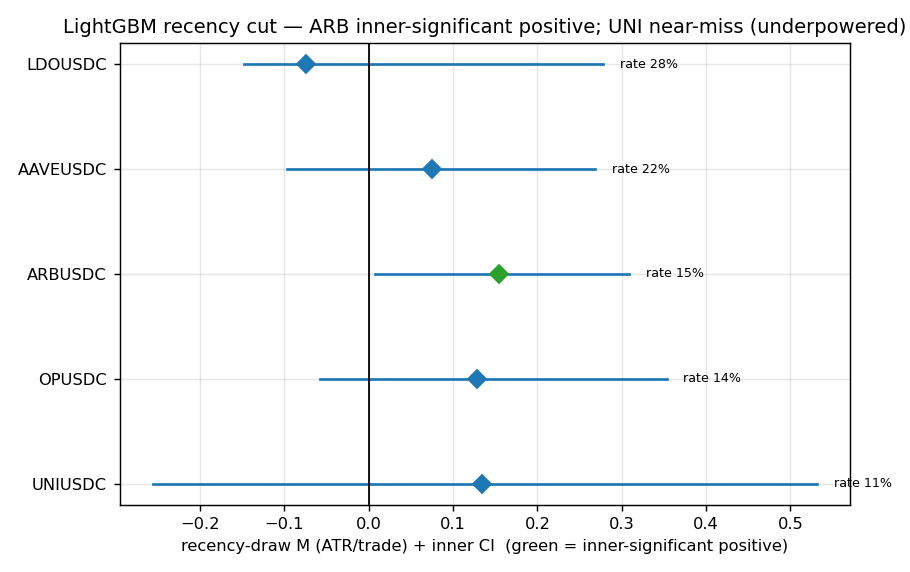 Figure 4. Recency-draw
Figure 4. Recency-draw M + inner CI per crypto. ARB is inner-significant positive (green); UNI is a
positive near-miss with a wide CI (underpowered); LDO negative.
5.4 Multiplicity & post-hoc selection — the mining is hypothesis-generating, NOT target-designating¶
The per-crypto decomposition re-imports the very winner's curse the gate corrects — onto two new axes:
- Crypto axis (10 cells). 5 cryptos × 2 families = 10 looks. Exactly one is inner-significant
(ARB-LGB, CI low +0.008 — at the very edge of zero). At ~5 %, ≈ 0.5 false positives are expected
across 10 looks → 1/10 is the chance level, not a discovery. No multiplicity correction is
applied. The naked
max{M : rate≥0.10}is itself an argmax-over-θ (biased high) per cell, so the optimism compounds across both axes (θ and crypto) before we even highlight the best cells. - Draw axis (recency). The recency cut is 1 of 6–12 draws — a third cherry-pick. That the recent
draw shows 9/10 cells gross-positive while the selection bootstrap (all draws) gives
p_pos ≈ 0is itself the proof that the recent draw is not representative — it is a favourable draw, exactly what selection variance produces.
Consequence for actionability. Naming "UNI/ARB-LightGBM" as the lead, or a "recency-focused" follow-up, would elevate post-hoc-selected cells + a post-hoc draw — the same sin the experiment exists to catch, displaced. The honest framing: the per-crypto mining is hypothesis-generating; it does not designate a target. It says only that if anything merits a high-power test, it is the generic high-confidence-tail mechanism — and any per-asset or recency-focused test must be justified independently (e.g. a genuinely improved HPO that lands on recent configs), not "this post-hoc draw looked good." Everything remains frozen behind S09.
6. Discussion¶
Three statements, at different confidence:
- No PROMOTE (pre-registered, decisive). No GBDT family is selection-robust + inner-significant + non-degenerate at gross cost on fold-3. The gate is correct; STOP.
- A hypothesis (point estimate, multiplicity-discounted) — not a result. On the recent config the
high-confidence tail looks discriminating (precision > 25 % at 10–16 % rate, ≈monotone). But across 10
cells only 1 is inner-significant (chance level, §5.4), the recent draw is a cherry-pick (selection
p_pos ≈ 0), the max is θ-biased, monotonicity has no null, and it is gross + binary-M. So this is a hypothesis to test under a pre-registered high-power protocol, not evidence of an edge. - Absence of evidence, not evidence of absence. Symmetric corollary: the gate's STOP is "not shown tradable here," not "no signal." Both over-readings — "tradable on UNI/ARB" and "signal dead" — are unsupported.
C_FRAGILE_TO_SELECTION (not GENERALISED_NOT_TRADEABLE) names the selection process — the per-cycle
HPO re-draw fails to land robustly — not necessarily the signal. The honest follow-up targets the generic
high-confidence-tail mechanism (config stability / meta-labeling on the top-confidence band — the LdP
thread of EK), not the post-hoc UNI/ARB cells. None of this generalises beyond GBDT, and all of it
is gated behind S09.
7. What we could NOT observe — and why¶
| Not observed | Why | Consequence |
|---|---|---|
| Independent replay/baseline fidelity (A6) | s43 used the s18 capture+replay; S09 is the independent check (A6 FAIL 5/5) |
verdict interpretation SUSPENDED; closure/ABANDON blocked until S09 |
| Full multi-fold economic envelope | gate STOPped before it (runs only on PASS) | no M(θ) envelope with multi-fold CIs |
| Folds {2, 4} (cross-fold) | cold-capture skipped by STOP | fold-3 in-sample on the fold axis; fold-3 could be the worst (or best) regime — uncharacterised (§8) |
| Cost-sensitivity curve | gross only | thin +0.1–0.3 ATR margins untested under real cost (likely erasing them) |
| Inner significance of the tail leads | B_sel = 200 + this run's draw count |
UNI/AAVE/OP-LGB central-positive but inner-underpowered → near-misses, not negatives |
| XGBoost / non-GBDT | per-trial archiving / out of scope | verdict is GBDT-minus-XGBoost |
M → economic magnitude |
M is ATR/trade (now known); ATR-in-% per asset not joined here |
absolute bps/annualised translation is a follow-up |
8. Threats to validity¶
- A6 (load-bearing). Replay fidelity unverified; if S09 returns
CANONICAL_DIVERGENCEthis run is void. - Single fold, in-sample on fold axis. STOP forgoes {2,4}; do not read as cross-fold. Cheap mitigation before any ABANDON: characterise fold-3's regime (volatility) vs {2,4}.
- Bootstrapping a maximum.
M = max_θ E(θ); the ordinary bootstrap is inconsistent for an extremum (subsampling / m-out-of-n needed). Does not movep_pos ≈ 0, but bites the borderline UNI/ARB CIs — exactly where a decision would turn. - θ axis not bootstrapped. Winner's curse corrected on the config axis, not θ; the rate floor is a binary patch — v2 reports the constrained frontier instead of the naked max.
- Multiplicity (the per-crypto axis). 10 cells + the recency draw axis + the max-over-θ compound the optimism; 1/10 inner-significant is chance (§5.4). No correction applied → the per-crypto positives are hypothesis-generating only, never a designated target.
- Binary-
M.Mcharges time-barrier closes the full SL (§3) — an approximation; the realized triple-barrier PnL is not used here. - Universe = 5 pairs, gross, fold-3.
Strengths. Pre-registered rule (no forking paths); complete cohort; decide-on-significance discipline (the recent-draw positivity is honestly not counted toward the verdict); per-crypto + frontier mined from the same data, then held to the same multiplicity standard (§5.4).
9. Conclusion & next steps (A6 first)¶
Pre-registered verdict C_FRAGILE_TO_SELECTION → STOP — no selection-robust, inner-significant,
non-degenerate edge at gross cost on fold-3. The per-crypto mining generates one hypothesis (a generic
high-confidence-tail mechanism) but, held to the same standard as the config axis, designates no target
(1/10 inner-significant = chance; recent draw unrepresentative — §5.4). Absence of evidence, not evidence
of absence, both ways.
- S09 FIRST — closure blocker. Clear the A6 replay caveat before any interpretation. No ABANDON, no
S05/version closure until S09. If
CANONICAL_DIVERGENCE, this verdict is void. - Pre-register a high-power test of the generic tail mechanism (not the post-hoc UNI/ARB cells):
permuted-label null for the monotone-precision claim, 10-cell multiplicity control, subsampling CIs
for the max-over-θ, real
cost_atr, and binary-Mreplaced by realized triple-barrier PnL. A per-asset or recency-focused variant needs an independent justification (e.g. an improved HPO that lands on recent configs), never "this draw looked good." - Meta-labeling / top-confidence-band as the candidate mechanism (high-precision, low-frequency, LdP/EK thread) — to be tested under (2), not assumed.
- Characterise fold-3 regime vs {2,4} before any cross-fold or ABANDON claim.
- Translate
M(ATR/trade) → bps/annualised per asset (join ATR-in-%) + measure the time-barrier close fraction (binary-Mvalidity, §3). - Feed into CVN-N001-EK as a provisional, multiplicity-discounted datum (pending S09) — not a graven KILL-tuple, and not a green light.
- Do not read as "signal dead for all models" — non-GBDT and classifier-quality (training-path F1) are untouched.
10. Reproducibility statement¶
- Run.
diagnostic__s43manual__2026-06-09T11:55:11+00:00,cost_atr=0.0,defi_top5, fold-3,skip_phase_a=false, image1cba660. - Frozen rule.
frac=0.95,RATE_MIN=0.10,B_sel=200,MIN_DRAWS=2(src/commun/finetune/diagnostic/s43_economic_tradability.py);Mfromtraining/harness/nodes/theta_curve.py(TP=1.5, SL=0.5 ATR). - Portfolio verdict. gate XCom +
scripts/airflow_xcom_pull.py --dag-id diagnostic__s43 --run-id <id> --task-id gate --json; Lokiscripts/loki_query.py --event s43_gate_outcome. - Per-crypto mining (Appendix A).
_data/s43_per_crypto_extract_inpod.py(in-pod, loads S3 predictions viaload_cohort_predictions, re-runsselection_bootstrap/theta_curveper crypto) →_data/s43_per_crypto_mining.json; figures_data/s43_figures.py.
Glossary¶
M(net expectancy) —max_θ E(θ), in ATR/trade (TP=+1.5, SL=−0.5 ATR; break-even precision 25 %), gross of cost.p_pos— fraction of selection resamples with inner-CI-low > 0 and rate ≥RATE_MIN. The pre-registered robustness key (decide on significance, not the point estimate).- degenerate rate — positive EV obtained only by trading < 10 % of candles → rejected by
RATE_MIN. - fragile / unstable —
sel_ci_high > 0with0 < p_pos < 0.95/p_pos = 0: edge in some draws, not robust / not establishable. - A6 — the replay-divergence caveat (s18 fidelity to prod unverified; subject of S09).
Appendix A — per-crypto mining provenance¶
_data/s43_per_crypto_extract_inpod.py runs inside the scheduler pod (S3 creds + code present),
reconstructs the run-isolated prefix s43-predictions/manual__2026-06-09T11_55_11_00_00, loads the cohort
predictions, and re-runs the same pure functions per crypto — no new training/cluster run (read-only
recompute on already-persisted predictions). Output _data/s43_per_crypto_mining.json; figures via
_data/s43_figures.py. The recompute is post-hoc and inherits the A6 caveat.